
〔AI〕神经网络
本文转载自:https://www.captainai.net/
什么是神经网络
从 1956 年夏季首次提出“人工智能”这一术语开始,科学家们尝试了各种方法来实现它。这些方法包括专家系统,决策树、归纳逻辑、聚类等等,但这些都是假智能。直到人工神经网络技术的出现,才让机器拥有了“真智能”。
为什么说之前的方法都是假智能呢?因为我们人类能清清楚楚地知道它们内部的分析过程,它们只是一个大型的复杂的程序而已;而人工神经网络则不同,它的内部是一个黑盒子,就像我们人类的大脑一样,我们不知道它内部的分析过程,我们不知道它是如何识别出人脸的,也不知道它是如何打败围棋世界冠军的。我们只是为它构造了一个躯壳而已,就像人类一样,我们只是生出了一个小孩而已,他脑子里是如何想的我们并不知道!这就是人工智能的可怕之处,因为将来它有可能会觉得我们人类不应该活在这个世界上,而把我们消灭掉;很多年前,麻省理工的 AI 博士群里就对此问题进行了非常激烈的讨论,大部分人都很担忧;为此,世界上已经成立了不少安全协会来防范人工智能。
人工神经网络是受到人类大脑结构的启发而创造出来的,这也是它能拥有真智能的根本原因。在我们的大脑中,有数十亿个称为神经元的细胞,它们连接成了一个神经网络。
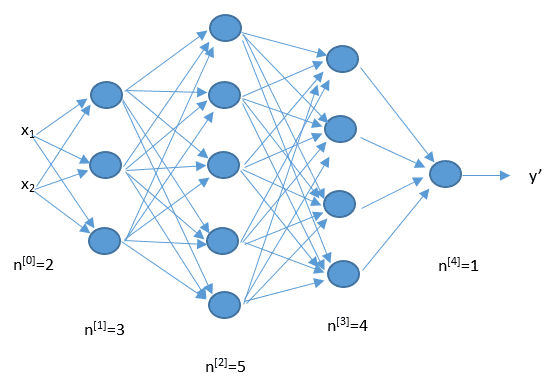
人工神经网络正是模仿了上面的网络结构。下面是一个人工神经网络的构造图。每一个圆代表着一个神经元,他们连接起来构成了一个网络。
人类大脑神经元细胞的树突接收来自外部的多个强度不同的刺激,并在神经元细胞体内进行处理,然后将其转化为一个输出结果。如下图所示。
人工神经元也有相似的工作原理。如下图所示。
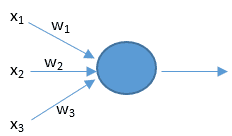
上面的 x 是神经元的输入,相当于树突接收的多个外部刺激。w 是每个输入对应的权重,它影响着每个输入 x 的刺激强度。
大脑的结构越简单,那么智商就越低。单细胞生物是智商最低的了。人工神经网络也是一样的,网络越复杂它就越强大,所以我们需要深度神经网络。这里的深度是指层数多,层数越多那么构造的神经网络就越复杂。
训练深度神经网络的过程就叫做深度学习。网络构建好了后,我们只需要负责不停地将训练数据输入到神经网络中,它内部就会自己不停地发生变化不停地学习。打比方说我们想要训练一个深度神经网络来识别猫。我们只需要不停地将猫的图片输入到神经网络中去。训练成功后,我们任意拿来一张新的图片,它都能判断出里面是否有猫。但我们并不知道他的分析过程是怎样的,它是如何判断里面是否有猫的。就像当我们教小孩子认识猫时,我们拿来一些白猫,告诉他这是猫,拿来一些黑猫,告诉他这也是猫,他脑子里会自己不停地学习猫的特征。最后我们拿来一些花猫,问他,他会告诉你这也是猫。但他是怎么知道的?他脑子里的分析过程是怎么样的?我们无从知道~~
如何将数据输入到神经网络中
我们需要弄懂的第一步就是如何将数据输入到神经网络中。例如,在百度的“小度智能屏”中,是如何将麦克风采集到的音频数据输入到神经网络中的;小度智能屏还能根据人脸来判断年龄从而自动切换成人和儿童模式,那它又是如何将摄像头采集到的人脸数据输入到神经网络中的。
下面我拿识别美女的例子来给大家介绍如何将美女的图片数据输入到神经网络中。
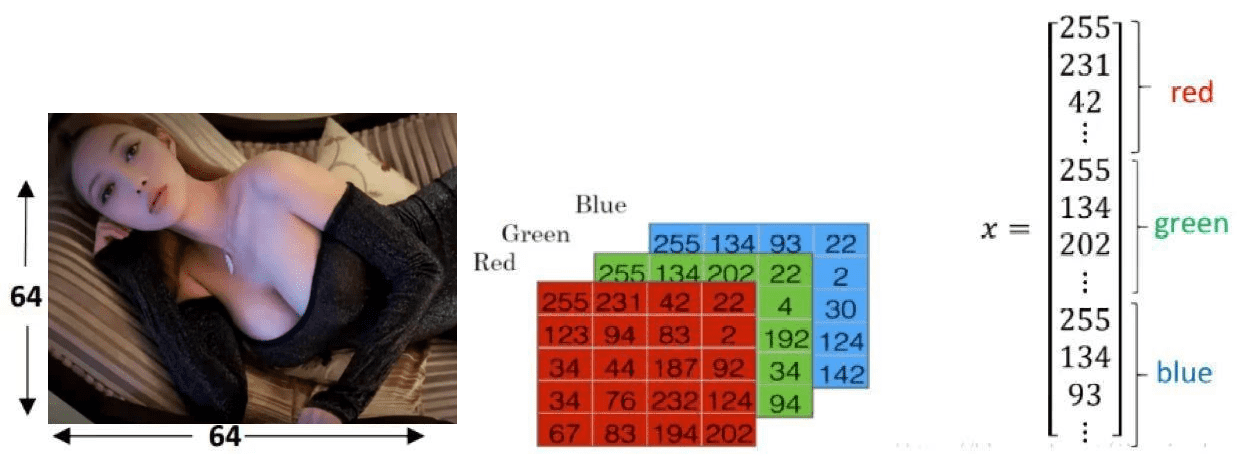
此例中,待输入的数据是一张图像。为了存储图像,计算机要存储三个独立的矩阵(矩阵可以理解成二维数组,后面的教程会给大家详细讲解),这三个矩阵分别与此图像的红色、绿色和蓝色相对应(世界上的所有颜色都可以通过红绿蓝三种颜色调配出来)。如果图像的大小是 64 * 64 个像素(一个像素就是一个颜色点,一个颜色点由红绿蓝三个值来表示,例如,红绿蓝为 255,255,255,那么这个颜色点就是白色),所以 3 个 64 * 64 大小的矩阵在计算机中就代表了这张图像,矩阵里面的数值就对应于图像的红绿蓝强度值。上图中只画了个 5 * 4 的矩阵,而不是 64 * 64,为什么呢?因为没有必要,搞复杂了反而不易于理解。
为了更加方便后面的处理,我们一般把上面那 3 个矩阵转化成 1 个向量 x(向量可以理解成 1 * n 或 n * 1 的数组,前者为行向量,后者为列向量,向量也会在后面的文章专门讲解)。那么这个向量 x 的总维数就是 64 * 64 * 3,结果是 12288。在人工智能领域中,每一个输入到神经网络的数据都被叫做一个特征,那么上面的这张图像中就有 12288 个特征。这个 12288 维的向量也被叫做特征向量。神经网络接收这个特征向量 x 作为输入,并进行预测,然后给出相应的结果。
对于不同的应用,需要识别的对象不同,有些是语音有些是图像有些是传感器数据,但是它们在计算机中都有对应的数字表示形式,通常我们会把它们转化成一个特征向量,然后将其输入到神经网络中。
神经网络是如何进行预测的
那么神经网络是如何根据这些数据进行预测的呢?我们将一张图片输入到神经网络中,神经网络是如何预测这张图中是否有猫的呢??
这个预测的过程其实只是基于一个简单的公式:z = dot(w,x) + b。看到这个公式,完全不懂。不用怕,看完我下面的解说后,你就会觉得其实它的原理很简单。就像玻璃栈道一样,只是看起来可怕而已。
上面公式中的 x 代表着输入特征向量,假设只有 3 个特征,那么 x 就可以用(x1,x2,x3)来表示。如下图所示。w 表示权重,它对应于每个输入特征,代表了每个特征的重要程度。b 表示阈值,用来影响预测结果。z 就是预测结果。公式中的 dot()函数表示将 w 和 x 进行向量相乘。我们现在只需要知道上面的公式展开后就变成了 z = (x1 * w1 + x2 * w2 + x3 * w3) + b。
那么神经网络到底是如何利用这个公式来进行预测的呢?下面我通过一个实例来帮助大家理解。
假设周末即将到来,你听说在你的城市将会有一个音乐节。我们要预测你是否会决定去参加。音乐节离地铁挺远,而且你女朋友想让你陪她宅在家里搞事情,但是天气预报说音乐节那天天气特别好。也就是说有 3 个因素会影响你的决定,这 3 个因素就可以看作是 3 个输入特征。那你到底会不会去呢?你的个人喜好——你对上面 3 个因素的重视程度——会影响你的决定。这 3 个重视程度就是 3 个权重。
如果你觉得地铁远近无所谓,并且已经精力衰竭不太想搞事情了,而且你很喜欢蓝天白云,那么我们将预测你会去音乐节。这个预测过程可以用我们的公式来表示。我们假设结果 z 大于 0 的话就表示会去,小于 0 表示不去。又设阈值 b 是-5。又设 3 个特征(x1,x2,x3)为(0,0,1),最后一个是 1,它代表了好天气。又设三个权重(w1,w2,w3)是(2,2,7),最后一个是 7 表示你很喜欢好天气。那么就有 z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 2 + 1 * 7) + (-5) = 2。预测结果 z 是 2,2 大于 0,所以预测你会去音乐节。
如果你最近欲火焚身,并且对其它两个因素并不在意,那么我们预测你将不会去音乐节。这同样可以用我们的公式来表示。设三个权重(w1,w2,w3)是(2,7,2),w2 是 7 表示你有顶穿钢板的欲火。那么就有 z = (x1 * w1 + x2 * w2 + x3 * w3) + b = (0 * 2 + 0 * 7 + 1 * 2) + (-5) = -3。预测结果 z 是-3,-3 小于 0,所以预测你不会去。
预测图片里有没有猫也是通过上面的公式。经过训练的神经网络会得到一组与猫相关的权重。当我们把一张图片输入到神经网络中,图片数据会与这组权重以及阈值进行运算,结果大于 0 就是有猫,小于 0 就是没有猫。
你平时上网时有没有发现网页上的广告都与你之前浏览过的东西是有关联的?那是因为很多网站都会记录下你平时的浏览喜好,然后把它们作为权重套入到上面的公式来预测你会购买什么。
上面那个用于预测的公式我们业界称之为逻辑回归,这个名字有点奇怪,大家记住就行了,只是个名字而已。
最后再稍微提一下激活函数。在实际的神经网络中,我们不能直接用逻辑回归。必须要在逻辑回归外面再套上一个函数。这个函数我们就称它为激活函数。激活函数非常非常重要,如果没有它,那么神经网络的智商永远高不起来。而且激活函数又分好多种。在本篇文章的末尾,我只给大家简单介绍一种叫做 sigmoid 的激活函数。它的公式和图像如下。
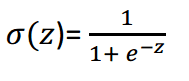
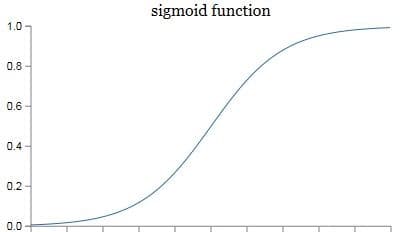
我们在这里先只介绍它的一个用途——把 z 映射到[0,1]之间。上图中的横坐标是 z,纵坐标我们用 y’来表示,y’就代表了我们最终的预测结果。从图像可以看出,z 越大那么 y’就越靠近 1,z 越小那么 y’就越靠近 0。那为什么要把预测结果映射到[0,1]之间呢?因为这样不仅便于神经网络进行计算,也便于我们人类进行理解。例如在预测是否有猫的例子中,如果 y’是 0.8,就说明有 80%的概率是有猫的。